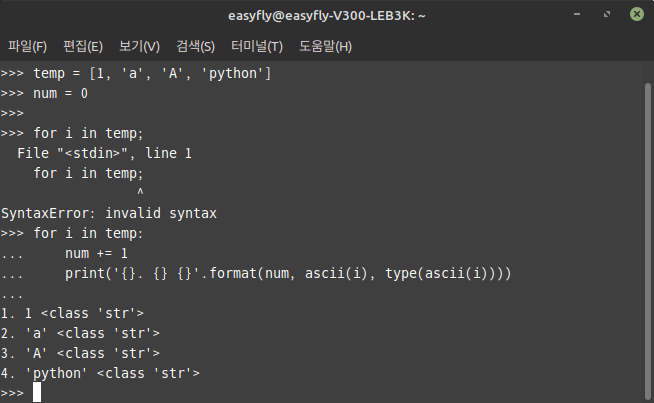
파이썬 내장 함수 repr()repr() 함수는 Python의 내장 함수 중 하나로, 객체의 문자열 표현(representation)을 반환합니다. repr() 함수는 주로 개발자용으로, 객체가 가지는 정보를 명확하고 정확하게 표현하는 문자열을 반환합니다. 이는 사람이 읽기 쉬운 형태라기보다는, 객체를 다시 생성할 수 있을 정도로 정확한 표현을 의도합니다.repr()의 특징:객체를 식별할 수 있는 문자열을 반환.반환되는 문자열은 객체를 다시 생성하는 데 사용할 수 있을 정도로 정확해야 함.개발 및 디버깅에 유용하게 쓰임.repr()와 str()의 차이:repr()은 디버깅과 개발 목적으로 객체의 정확한 표현을 반환합니다.str()은 사용자에게 읽기 쉬운 형식으로 객체를 반환합니다.# 예시 코드x = 12..