유니코드와 UTF-8
유니코드는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준입니다. 이는 각 문자에 고유한 코드 값을 할당하는 방식으로, 다양한 언어와 기호를 하나의 통합된 시스템 내에서 처리할 수 있게 합니다.
유니코드
유니코드는 전 세계의 모든 문자에 대해 코드 포인트를 할당합니다. 이 코드 포인트는 U+0000부터 U+10FFFF까지 확장될 수 있으며, 이는 약 110만 개의 가능한 문자를 포함합니다. 유니코드는 다양한 문자 집합을 지원하며, 각 문자에 대한 유니크한 식별자를 제공합니다. 이는 서로 다른 언어 및 스크립트 간의 데이터 교환을 원활하게 하고, 소프트웨어 및 시스템의 국제화를 촉진합니다.
UTF-8
UTF-8은 "Unicode Transformation Format - 8-bit"의 약자로 유니코드 문자를 인코딩하는 방법 중 하나입니다. UTF-8은 유니코드 문자를 저장하기 위해 1바이트에서 4바이트까지 가변적으로 사용합니다. 이 인코딩 방식은 유니코드의 코드 포인트를 바이트 시퀀스로 변환하여 표현합니다.
- 1바이트는 기본 ASCII 세트(0x00에서 0x7F)를 그대로 사용합니다.
- 2바이트는 보통 0x80에서 0x7FF 범위의 문자를 인코딩합니다.
- 3바이트는 대부분의 현대 문자를 포함하며, 0x800에서 0xFFFF까지의 문자를 처리합니다.
- 4바이트는 매우 드물게 사용되며, 0x10000에서 0x10FFFF 범위의 코드 포인트를 인코딩합니다.
UTF-8의 주요 장점은 호환성입니다. 기존의 ASCII 텍스트는 UTF-8로 인코딩된 텍스트와 완벽하게 호환되므로, 이전 데이터와의 호환성 문제없이 새로운 시스템으로 이전할 수 있습니다. 또한, 이 인코딩 방식은 인터넷에서 널리 사용되며, 웹 페이지와 이메일 전송에 기본적으로 채택되어 있습니다.
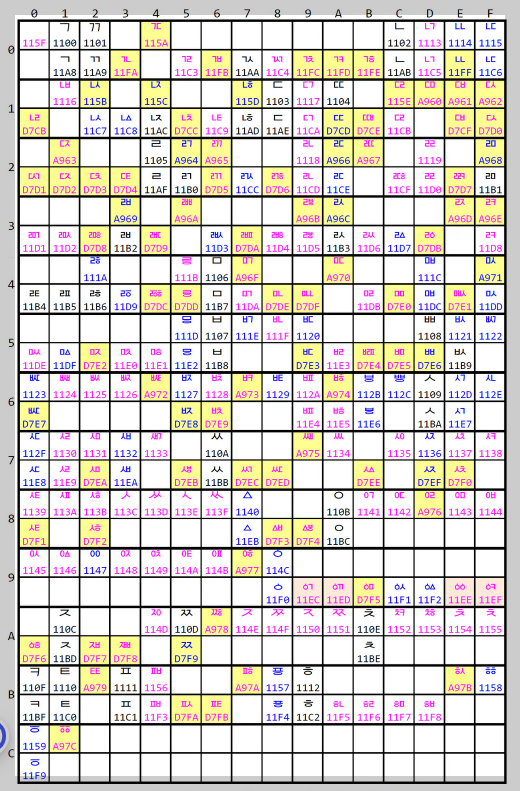
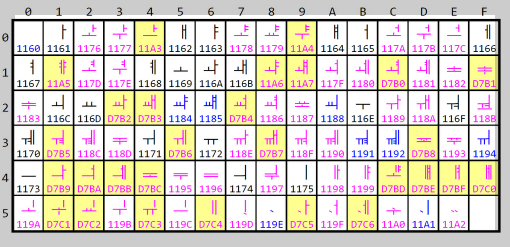
정리
유니코드와 UTF-8은 세계화된 현대 컴퓨팅 환경에서 필수적인 역할을 하며, 다양한 언어와 문화의 정보를 쉽게 교류할 수 있는 기반을 제공합니다.
'실버를 위한 코딩' 카테고리의 다른 글
| [컴퓨터] 유니코드와 한자(漢字) (0) | 2024.05.01 |
|---|---|
| [컴퓨터] UTF-8, UTF-16, UTF-32의 차이는? (0) | 2024.04.30 |
| [컴퓨터] 한국어 문자 인코딩 방식인 코드 페이지 949, CP949 (0) | 2024.04.28 |
| [컴퓨터] 문자 체계에 대한 이해, EUC-KR (0) | 2024.04.27 |
| [컴퓨터] 아스키 코드(ASCII, American Standard Code for Information Interchange) (2) | 2024.04.26 |